Enterprise LLM Observability
As LLMs become mission-critical to business operations, maintaining visibility and control is paramount. Our AI Gateway provides comprehensive monitoring, analytics, and tracing capabilities to help you optimize performance, detect issues, and control costs across your AI infrastructure.
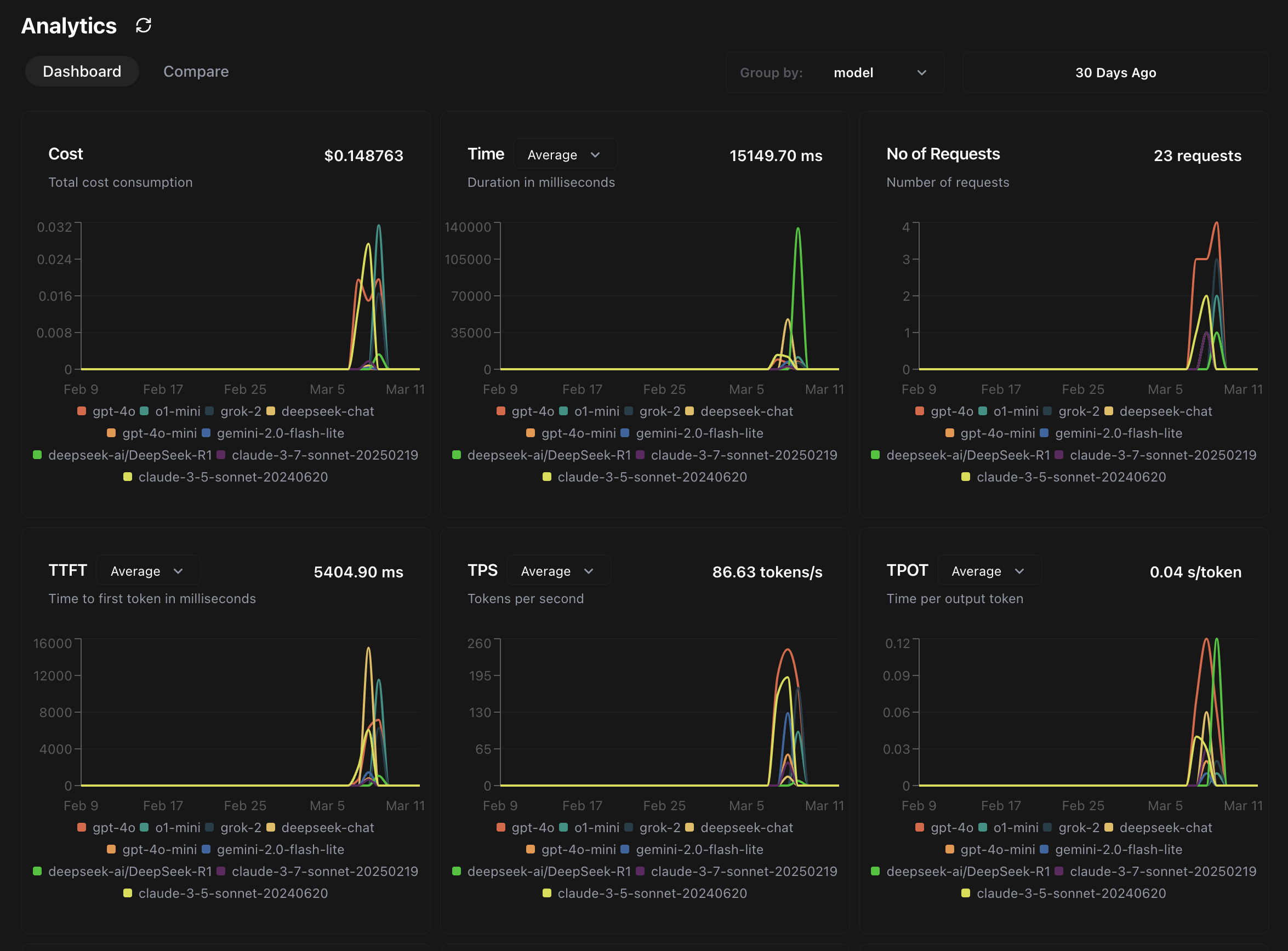
Get complete visibility into your AI applications with enterprise-grade observability that helps you monitor, analyze, and optimize your LLM operations.
Our comprehensive LLM Observability Platform provides real-time insights into performance, costs, and reliability across your entire AI stack.
The LLM Observability Challenge
Without robust observability, LLM applications pose significant risks to enterprises:
Critical Visibility Gaps
- Performance Blindspots: Unable to track latency and throughput issues
- Cost Uncertainty: Difficulty tracking token usage and expenses
- Quality Issues: No way to detect hallucinations or response quality
- Debugging Complexity: Limited ability to trace issues across systems
- Usage Attribution: Can't track usage by team or application
Observability Requirements
- Real-time Monitoring: Track performance and usage in real-time
- Cost Analytics: Detailed tracking of token usage and expenses
- Quality Assurance: Detect and prevent hallucinations
- End-to-End Tracing: Full visibility into request flow
- Usage Attribution: Track usage by team and application
Four-Pillar Observability Architecture
Our comprehensive observability system combines multiple monitoring approaches to ensure maximum visibility and control.
Performance Monitoring
Real-time tracking of critical performance metrics across your LLM infrastructure.
- •Latency Tracking: Monitor request and response times
- •Throughput Analysis: Track requests per second
- •Error Rate Monitoring: Track failed requests
- •Resource Usage: Monitor system resources
Cost Analytics
Detailed tracking of token usage and costs across your LLM applications.
- •Token Usage: Track consumption by model
- •Cost Attribution: Track expenses by team
- •Budget Alerts: Set spending thresholds
- •Cost Optimization: Identify savings opportunities
Quality Assurance
Monitor and maintain the quality of your LLM outputs.
- •Hallucination Detection: Identify false outputs
- •Response Validation: Check output quality
- •Content Safety: Monitor for harmful content
- •Automated Testing: Continuous quality checks
End-to-End Tracing
Complete visibility into your LLM request flow.
- •Request Tracing: Track full request lifecycle
- •Dependency Mapping: Visualize system dependencies
- •Error Tracking: Identify failure points
- •Performance Analysis: Find bottlenecks
Ready to Monitor Your AI Applications?
LangDB's observability platform provides the visibility you need to deploy AI with confidence. Our comprehensive approach ensures your AI systems operate efficiently, reliably, and cost-effectively.
Resources
Explore our comprehensive documentation to learn more about implementing LLM observability.