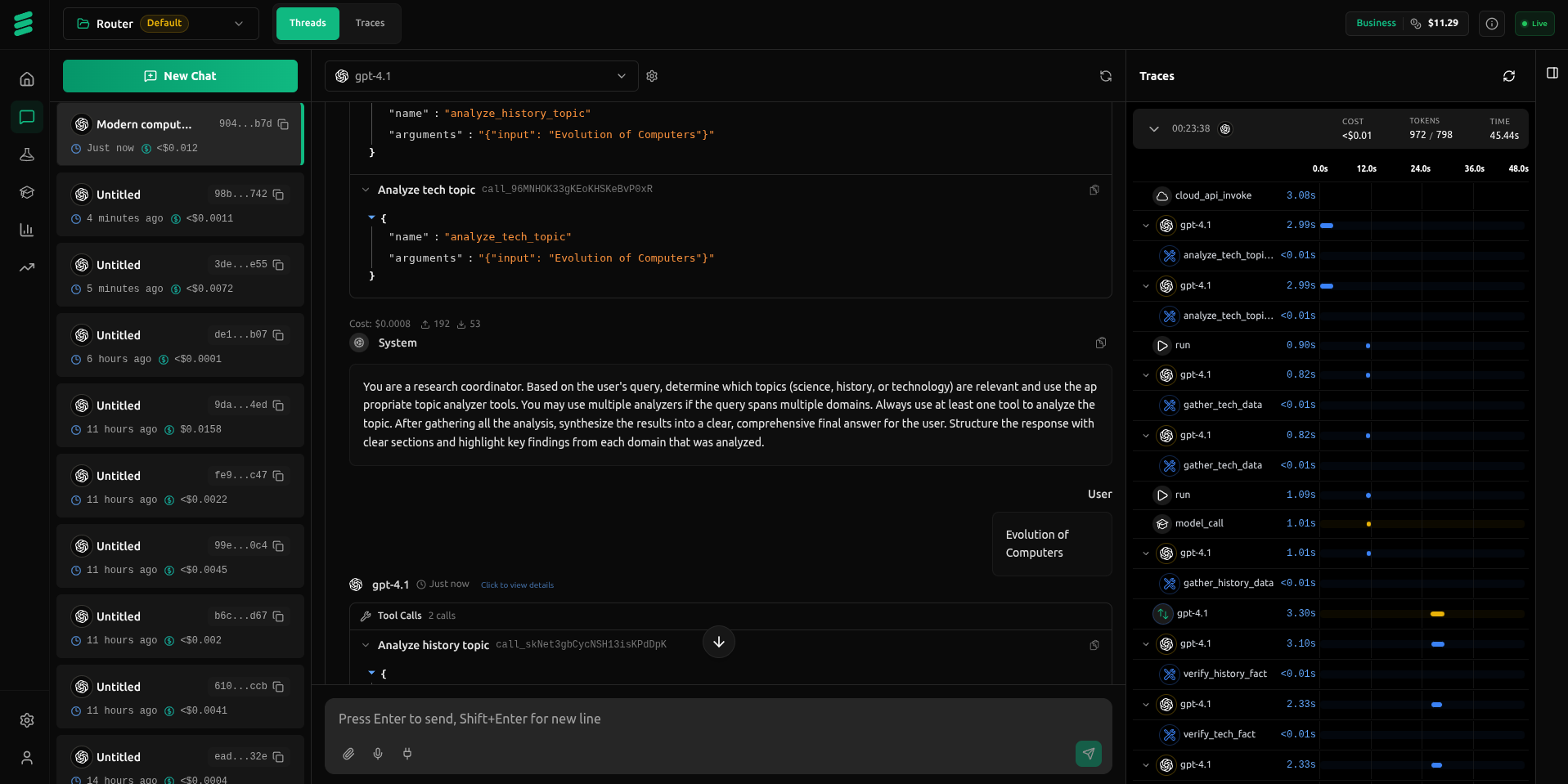
Debug Your Agents
in Real Time
Comprehensive observability for AI agents. Trace, analyze, and optimize with real-time monitoring across LangChain, Google ADK, OpenAI, and all major frameworks.
Open Source
Run observability stack locally
We've open-sourced our observability as vLLora. Trace, analyze, and optimize your AI agents with tools that work seamlessly with LangChain, Google ADK, OpenAI, and all major frameworks.
Fully Built in

The Command Center
for All AI Workflows
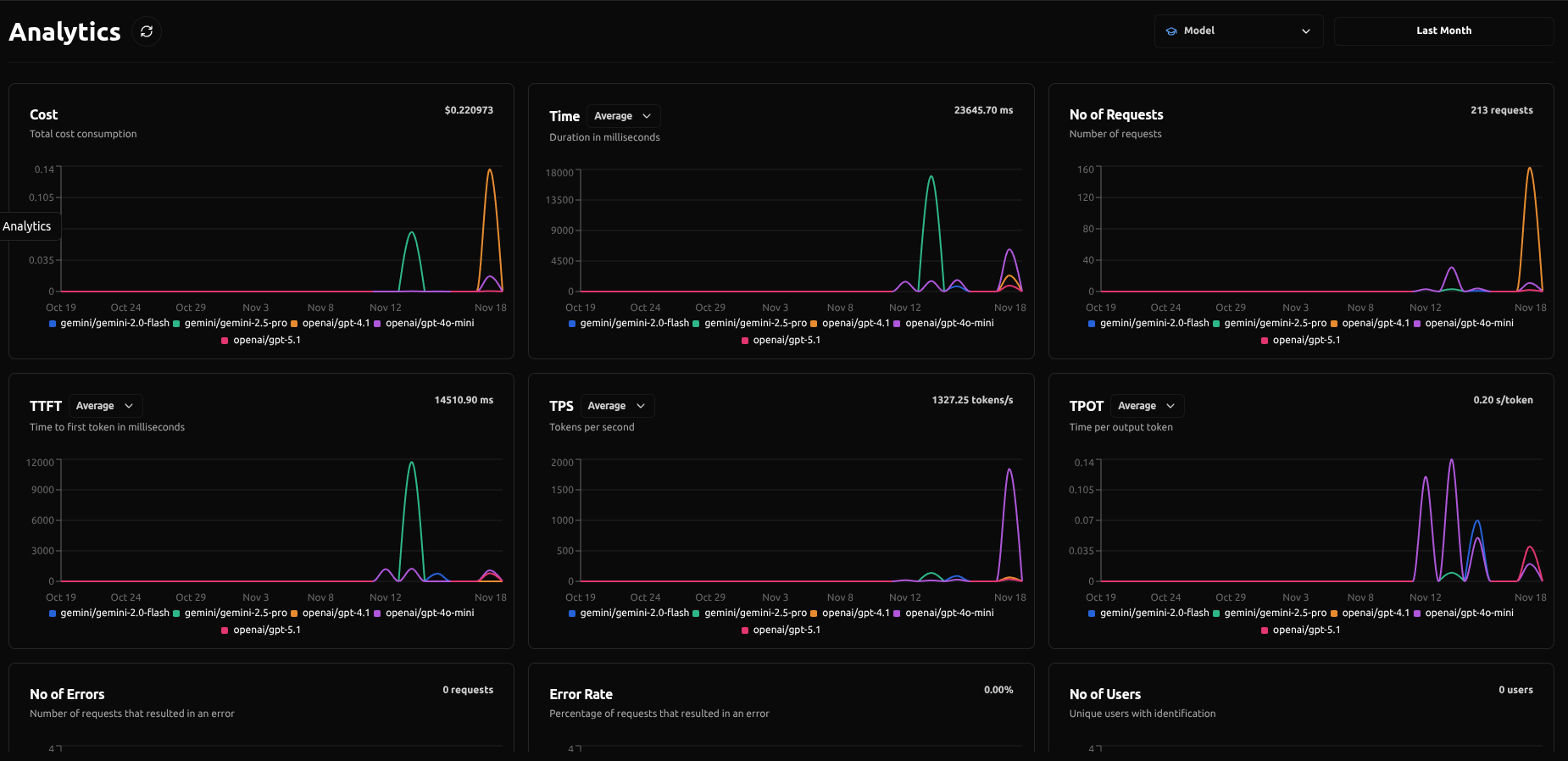
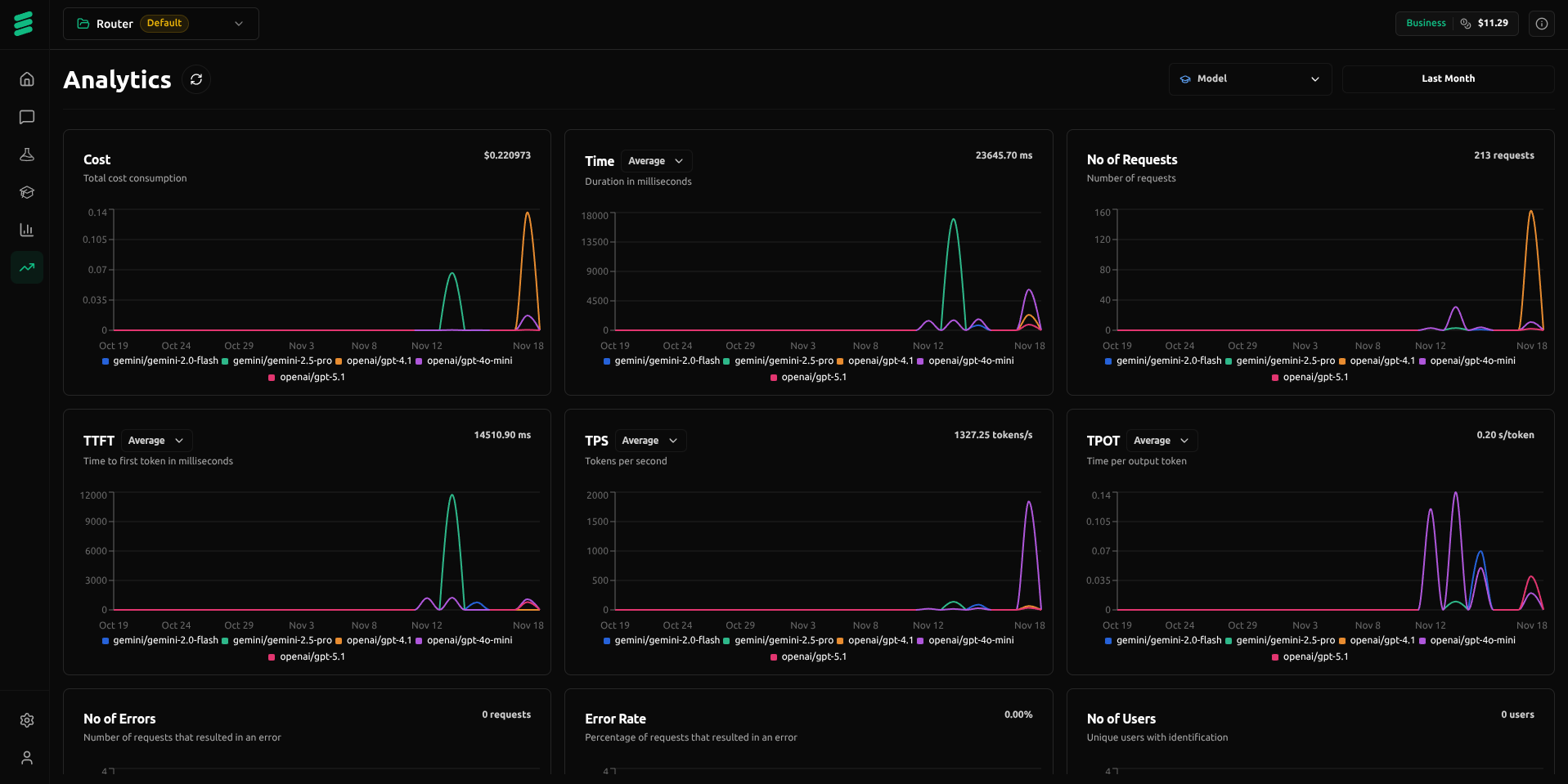
Advanced LLM Analytics
Unlock real-time insight into LLM performance, usage, and effectiveness so you can make data-driven decisions that keep AI operations optimized.
Designed for Scale and Performance
LangDB is the only AI gateway fully built in Rust, guaranteeing performance and scalability unachievable by gateways written in Python or JavaScript.

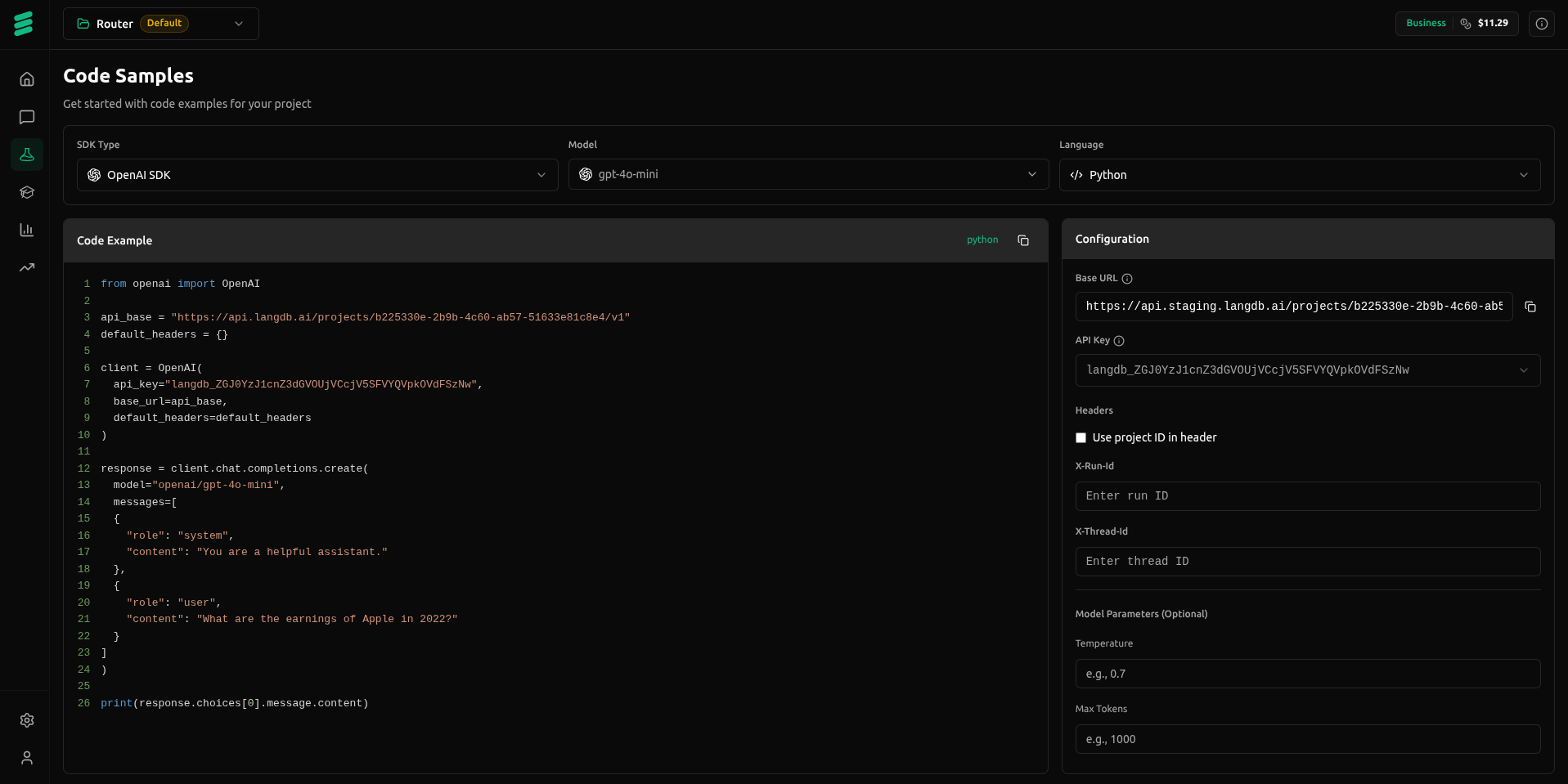
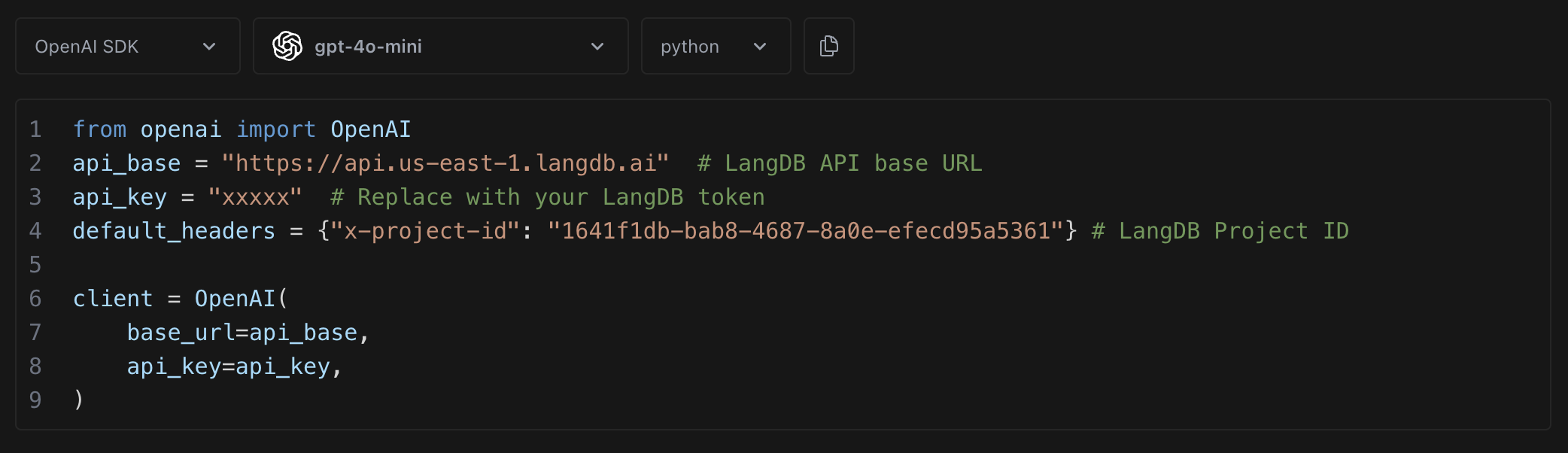
Integrate in Minutes Framework-Agnostic. No pip or npm Installs.
Backed by
